












{kind=link}
{kind=link}
Similarly to their AES Fall 2020 New York show, the Audio Engineering Society’s AES Show Spring 2021 convention, though “located” in Europe, was conducted virtually –which allowed a New Yorker like myself to attend online and enjoy multiple workshops, demonstrations and symposiums that would have been physically and logistically impossible in real-time. The show, appropriately named “Global Resonance,” took place from May 25 – 28.
Among the hot topics were binaural recording, Dolby Atmos and other forms of immersive 3D audio such as Ambisonics, along with psychology-based audio perception, and tech-related issues involving digital and analog gear.
In the 1970s, experiments in binaural recording, conducted via situating microphones in mannequin dummy heads in order to simulate how humans hear, became a trend, with musicians such as Lou Reed becoming particularly impassioned advocates. Reed’s Street Hassle album and live concert recording Take No Prisoners were credited as being recorded in the binaural format. As an attendee at one of Lou Reed’s New York City shows at the Bottom Line where Take No Prisoners was recorded, I can attest to at least half a dozen dummy heads being situated in different locations inside the 400-seat venue, used for remote recording of the concerts.
As personal music listening on headphones has increased exponentially over the last two decades, with audiophile-grade headphones now in great demand, binaural recording has been given a second look. It can now be combined with current digital technology to achieve even greater detail and a more realistic sense of 3D spaciousness and depth within the stereo field than any previous attempts.
With this in mind, Martin Schneider presented a comprehensive overview on the topic: “The Development of Dummy Head Microphones Since 1970.” Schneider’s thorough research yielded a number of previously obscure facts, such as:
- Photographs show that experimentation into the idea of recording with dummy heads to simulate human hearing perspectives dates back to the 1930s at Bell Labs, as well as at Wilska in Finland and Philips in The Netherlands.
- Interest perked up again in the 1960s in Berlin with research from AKG and Sennheiser.
- Neumann spearheaded 1970s development with its KU80 mics, which Schneider refers to as the start of the “Golden Age” of dummy head recording. This resulted in a significant amount of German binaural music recording and radio drama production.
- Neumann continued to innovate in the 1980s and 1990s with their KU81 and KU100 mics, while additional R&D was conducted by Bruel & Kjaer, HEAD Acoustics, and Cortex.
In addition to recording and live broadcast applications, dummy head microphones were used in audiology (i.e., the development of hearing aids and testing tools), psychoacoustics, industrial applications such as automotive and spatial sound design, room acoustics and environmental noise measurement, HRTF (head-related transfer function) and impulse response research, and for video game development (for the creation of sonic virtual reality).
 Screen shot from "The Development of Dummy Head Microphones Since 1970" by Martin Schneider, courtesy of AES.
Screen shot from "The Development of Dummy Head Microphones Since 1970" by Martin Schneider, courtesy of AES.Dummy heads also have been built in a variety of configurations:
- Head and torso simulators
- Head with ears (most common) with asymmetrical ears for recording or symmetrical ears for measurement
- “Headless” sphere mics without ears
- Dummy heads with in-ear or on-ear mics
- A live person wearing in-ear or on-ear mics
- Female and child heads (for different size/height ratio perspectives)
Additionally, placement of the microphones within various parts of the dummy head ears can yield different sound qualities, so mics can simulate reception of sound anywhere from outside to inside the ear canal up to the eardrum itself. The generally-preferred location for recording is the blocked-ear-canal position, since it contains all of the directional information available for 3D sound.
By and large, omnidirectional measurement condenser microphones are the most frequently deployed type of mics used in dummy heads, followed by studio condenser mics and battery-powered mini electret condenser mics (the most affordable option). Since the goal of binaural recording with dummy head mics is to achieve the greatest level of human hearing simulation, external processing units are generally eschewed. Battery power or phantom power options are used to keep the recorded signal as “all in the mics” as possible.
As radio broadcasts using dummy head recording exhibited field diffusion issues when listened to on loudspeakers (that is, the binaural effect is diminished compared to when listening using headphones), Schneider also compared the post-production EQ techniques by both electrical and acoustical means to filter or compensate for dummy head mic limitations.
Different sizes of heads, including models that compensated for the potential muting effects from different types of hair, and different types of ear/mic arrays, (such as the Neumann KU81 and later the KU100), provided flatter diffuse-field EQ curves and massively increased dynamic range going into the 1990s. Schneider took his presentation into the present day by showing that dummy head recording, once a relatively obscure field, is now being given greater consideration because of today’s demands for ever-more-realistic 3D sound from audiophiles and the virtual reality industry.
Additional AES presentations on 3D audio involved studies showing sound capture techniques used for 9-channel immersive audio mixing, the use of 3-channel spot microphone arrays to reproduce the auditory width of individual acoustic instruments, and stereo-width perceptual optimization control methods of 3D audio reproduction for headphone listening.
While 3D audio for music is certainly of great interest to Copper readers, a close second, at least for me, is film sound, a field which pioneered much of the immersive sound techniques and standards in use today. Of particular interest was a presentation by Ahmed Gelby entitled “Mix Translation: Optimizing the Cinema Sound Experience for a Domestic Setting.”
Gelby recounts a common problem that I have frequently encountered personally: when watching movies or shows on television, the dynamic range is so wide that explosions and other sounds require turning the volume down so as not to disturb sleeping children or neighbors, especially in apartment dwellings, yet doing so renders dialog to be so low in volume as to be indecipherable. This occurrence is so common that Gelby did a study on it and identified both the underlying reasons for this situation, as well as some possible remedies. [For this reason, some TVs have a “night mode” that compresses the dynamic range for late-night, low-volume listening. I’ve never found it satisfactory. – Ed.]
Gelby cites that domestic listening equipment and gear deviates widely from SMPTE (Society of Motion Picture and Television Engineers) and other industry standards, as attested to by re-recording mixers and engineers within the film and TV industries. He also notes the subjective nature of film and TV sound mixing and the lack of documentation within the industry for engineers and other professionals for addressing these disparities.
 Head and torso dummy head binaural recording mics. Courtesy of Wikipedia Commons/2014AIST.
Head and torso dummy head binaural recording mics. Courtesy of Wikipedia Commons/2014AIST.
At the film mixing stage, engineers generally mix at a reference of 85 dB/C and under acoustic conditions akin to what the sound would be like in a theater. On occasion, mixers with foresight will use actual TV speakers in the dubbing stage as a separate reference. Film genres can also influence mixes, with comedies having louder dialog and subtler background music and wild sounds. Horror or sci-fi genres will frequently amplify sound effects much more prevalently, with music cues often being heavily compressed for maximum impact level in building climaxes.
At the mastering stage, streaming and broadcast video distributors have delivery specs with loudness targets, peak limits and gate requirements to comply with regional or national telecom regulations.
Gelby conducted surveys from home viewers as well as professional engineers to get data points on listening habits and preferences. Surprisingly, a majority of engineers cited a preference for reducing the volume of sound effects and music in programming, while, as expected, the bulk of viewers who watched at home also preferred louder dialog, especially those who used the built-in speakers in their televisions.
A significant discrepancy was that most mixers listened within a short distance from their near-field monitors when mixing in rooms that averaged between 1,500-5,000 square feet, and did not compensate for dialog intelligibility in domestic listening conditions. Given that the increasing majority of films are viewed at home, especially since the pandemic, cross-reference monitoring on actual TV speakers for dialog clarity can now be considered a crucially essential component of the monitoring mix chain for film and video.
A number of mixers did comment that they were aware that their mixes translated differently between theatrical, Blu-ray/DVD and streaming platforms, but had no control over how audio dynamic range compression or other elements within streaming protocols between Netflix, Amazon Prime, Hulu, et al. might vary.

 A Dolby Atmos-certified sound mixing theater at CineLab, Moscow. Courtesy of WIkimedia Commons/Dirrtyjerm.
A Dolby Atmos-certified sound mixing theater at CineLab, Moscow. Courtesy of WIkimedia Commons/Dirrtyjerm.
Hip-hop has become the most popular form of current music around the globe, with representative artists from nearly every nation. Stripped down to its core, hip-hop is a repeating rhythm and a voice. Artistic additions such as melodic refrains, musical riffs, sampled sound effects and other elements from different cultures and creative imaginations are the sonic and musical variations that define individual artists and categorize sub genres within hip-hop.
Perhaps one of the most fascinating presentations of AES Spring 2021 was “Timbre-Based Machine Learning of Clustering Chinese and Western Hip-Hop Music.” Presented by Rolf Bader, the study took 38 examples of Western hip-hop from the US, UK, Germany and France, and compared them with 38 examples of Chinese and Taiwanese hip-hop music. The criteria for selection was predicated on impact, music history, originality, and large prominence.
The analysis procedure was as follows:
Using Computational Phonogram Archiving, the researchers ran algorithms for musical information retrieval that would take timbre, SPL, spectral width, and other audio factors and post them in a Kohonen self-organizing map to cluster the pieces. Created in 1980 by Finish scientist Teuvo Kohonen, a Kohonen Self-Organizing feature map (SOM) refers to a neural network, which is trained using competitive learning. Basic competitive learning implies that the competition process takes place before the cycle of learning. The competition process suggests that some criteria select a winning processing element.
- Artificial intelligence machine learning vectors would develop from the integrated mean and standard deviation of the separated timbre elements.
- The combining features in the vectors would then cluster the Chinese/Taiwanese and Western hip-hop music elements.
The presentation also reviewed the technical aspects of the study, such as mic arrays, acoustics, synthesis, and other audio criteria used, as well as the references from a musicology and historical context, which included past studies in speech and ethnomusicology including percussion-based music such as Indonesian gamelan music, African xylophones, flamenco, and other genres.
 Flowchart of analysis data points for "Timbre-Based Machine Learning of
Flowchart of analysis data points for "Timbre-Based Machine Learning ofTo the researchers’ surprise, no integrated mean of a timbre feature resulted in a cluster. Only a few timbre standard deviations led to clusters, and no clear clusters could be found from among the Western hip-hop examples.
The primary standard deviation cluster was SPL (sound pressure level), and showed that Chinese/Taiwanese hip-hop was mastered with high compression on a consistent basis whereas Western hip-hop uniformly had much lower compression. This would indicate that Chinese-language hip-hop music is apparently preoccupied with winning the “loudness wars.”
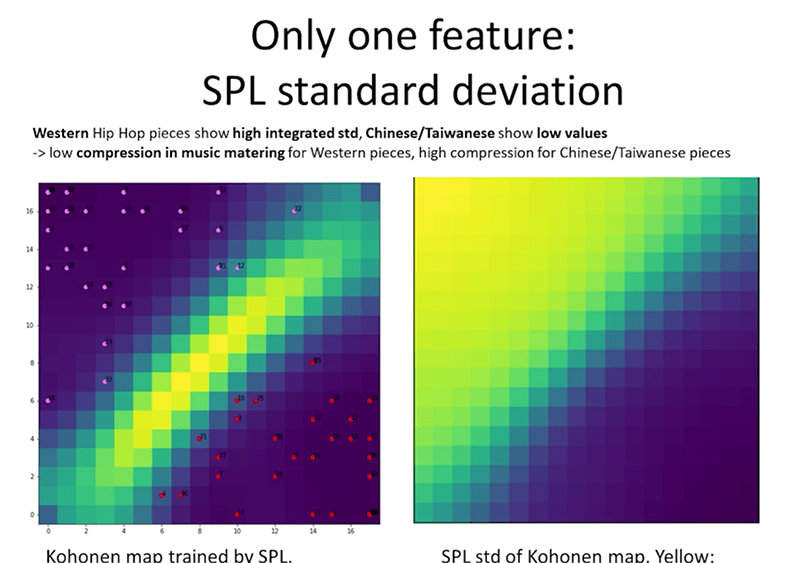 Kohonen maps from "Timbre-Based Machine Learning of Clustering Chinese and Western Hip-Hop Music," by Rolf Bader. Courtesy of AES.
Kohonen maps from "Timbre-Based Machine Learning of Clustering Chinese and Western Hip-Hop Music," by Rolf Bader. Courtesy of AES.In the “roughness” and “sharpness” timbre categories, Western hip-hop also appeared to be “busier,” with more layers of abrupt sounds going on, than the comparatively smoother Chinese and Taiwanese hip-hop.
In the “centroid” category, Western hip-hop contained a greater degree of variation with its musical format themes, key changes, and had heavier bass and lower-midrange content, and other aspects compared to Chinese/Taiwanese hip-hop, which was more focused on a single theme with perhaps one alternate part and a greater degree of theme repetition in each piece. Tonally, it sometimes exhibited larger fluctuations in brightness (high-frequency response).
AES Spring 2021 Europe definitely emphasized a stronger academic perspective than what was found in New York’s AES Show Fall 2020. In Part Two, we will review other presentations dealing with psychoacoustics, streaming technology, and other topics.
0 comments